紧接着上一篇的内容,在上一篇我们大致介绍了关于A3C的起源:actor-critic,以及在此基础上的补充:借助多线程实现多智能体的共同协作探索,并行计算梯度,从而打破了样本件的相关性 ;
在开始说实现之前,像先基于DQN的experience replay方法和A3C的asynchronous来说一下关于off-policy和on-policy;
首先我们要知道两者的来源。强化学习的目的是期望获得最优策略,也就是一种确定性的「状态-最优action」这样一个state和action的分布对应的映射,也就是target policy;
在求取这个target policy的过程中,on-policy和off-policy的思路不同;on-policy就是针对性的探寻这样一个target policy,就像SARSA一样,在这个过程中一边基于一定的要求选择action 一边对应的来对于Q值函数进行更新;但这个过程中会带来局部最优的问题,也就是只利用当前最优选择 学不到整体最优,再放大了说 就是探索和利用的矛盾;因而ε-greedy的设计在一定程度上解决了这个问题;
而off-policy的思路不同,它并不是直接的就是学习得到target policy,而是先基于某分布下的大量行动数据 目的在于探索,参考qlearning里面进行q值更新时候的max 选取的就是其中的最优选择,进而在现有的这个分布情况或者说现有行为策略下进行学习优化得到target policy;于是这样,我们可以看到qlearning里面,行动策略是一方面,而优化的过程中 也就是q值的优化是取$s_{next}$对应action当前的q值max的一个,也就是这样完成了从behavior policy到target policy
这里只是随手写的一些,感觉说法不对,后期比对RL:introduction 再重写一下;
然后再说 两种方法的优劣:
on-policy优点是直接了当,速度快,劣势是不一定找到最优策略。
off-policy劣势是曲折,收敛慢,但优势是更为强大和通用。其强大是因为它确保了数据全面性,所有行为都能覆盖。「这里所说的就是在选取$s_{next}$对应action的时候需要选取max的一个 那么需要全部action的q值 于是覆盖了全部的行为,相比之下on-policy只是单纯的依照策略选取了某个action;」
然后再说关于DQN里面的experience replay方法和A3C的asynchronous;前者在DQN里面使用的时候是在对估计Q(s,a),estimate_Q(s, a) = r + lamda * maxQ(s2, a) ,如果按照on-policy理解的话 这个时候的应该是estimate_Q(s, a) = r + lamda * Q(s2, a2) ,但事实上 这个时候相当于按照之前存储的经验进行更新的「储存的经验是在memory里面 随机抽样得到的 于是也就包含之前的经验」所以说 选取a2依据的参数和当前episode里面的参数是不一样的「比如依据ε-greedy选取action,更新时候的episode和存储时候的episode不一样了,那么ε也会变化;同时用来估计Q(s2, a2)时的Q网络经过更新已经不再时做出a2是的Q网络,因此Q(s2, a2)也不再是基于当时behavior policy的估计了。 」
因而experience replay中还是适合off-policy的方法;Actor-critic应该是可以使用experience replay的 ;
而asynchronous的方法 因为是多线程同时进行优化,也不就像experience replay方法那样对于on-policy有着限制,多个并行的actor可以有助于exploration。在不同线程上使用不同的探索策略,使得经验数据在时间上的相关性很小。这样不需要DQN中的experience replay也可以起到稳定学习过程的作用,意味着学习过程可以是on-policy的。
A3C的实现
全部实现在:https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/blob/master/contents/10_A3C/A3C_continuous_action.py
三个A的理解
- A3C的全名是Asynchronous Advantage Actor-Critic ,顾名思义 是异步的架构;并非像DQN那样仅单智能体与单环境交互,A3C可以产生多交互过程;如下图可知 A3C包括一个主网络 和多个工作的有着各自参数的agent,同时的和各自的环境进行交互;相比于单个的agent 这种方法更有效之处在于 因为来自各自独立的环境 于是采集得到的经验也是独立的 于是采集得到的经验也更多元化;
- 说完了异步(asynchronous) 然后说到actor-critic,相比于单纯的值迭代方法如:qlearning 和 策略迭代方法如:策略梯度的方法;AC有这两者的优势;在本实践之中,本网络可以既估计值函数 $V(s)$「某确定的的状态有多好」而且还能输出策略$\pi(s)$「动作概率输出的集合」;参考上图知道 也就是在全连接层之后的不同输出;AC方法的关键之处在于:agent采用值估计「critic」来更新策略「actor」相比于传统的策略梯度的方法更有效;
- 回头看一下关于之前策略梯度的完成,其中关于损失函数的构建是直接使用的reward的折扣累计来实现的;emmmm 关于这部分策略梯度损失函数两部分的含义可以参考这个网页 或者是之前的A3C文章 于是在之前的策略梯度中的网络是根据这个折扣reward得到的关于该action好与坏的评价来进行对该action的鼓励亦或是阻止; 这里采用advantage来替代传统的折扣reward累计;不光是能让agent判断action是否是好 而且能让其判断比预期好多少;intuitively (直觉的) 这样可以允许算法去更针对那些预测不足的区域 具体的可以参考之前的 dueling q network的架构:其中关于 $Advantage: A=Q(s,a)-V(s)$;
在A3C中并不能直接确定Q值(?) 于是这里采用折扣reward来作为Q(s,a)的估计 来生成关于advantage的估计:$A=R-V(s)$ 同时 本教程之中又进行了修改 使用的是另一种有着更低方差的版本:Generalized Advantage Estimation.
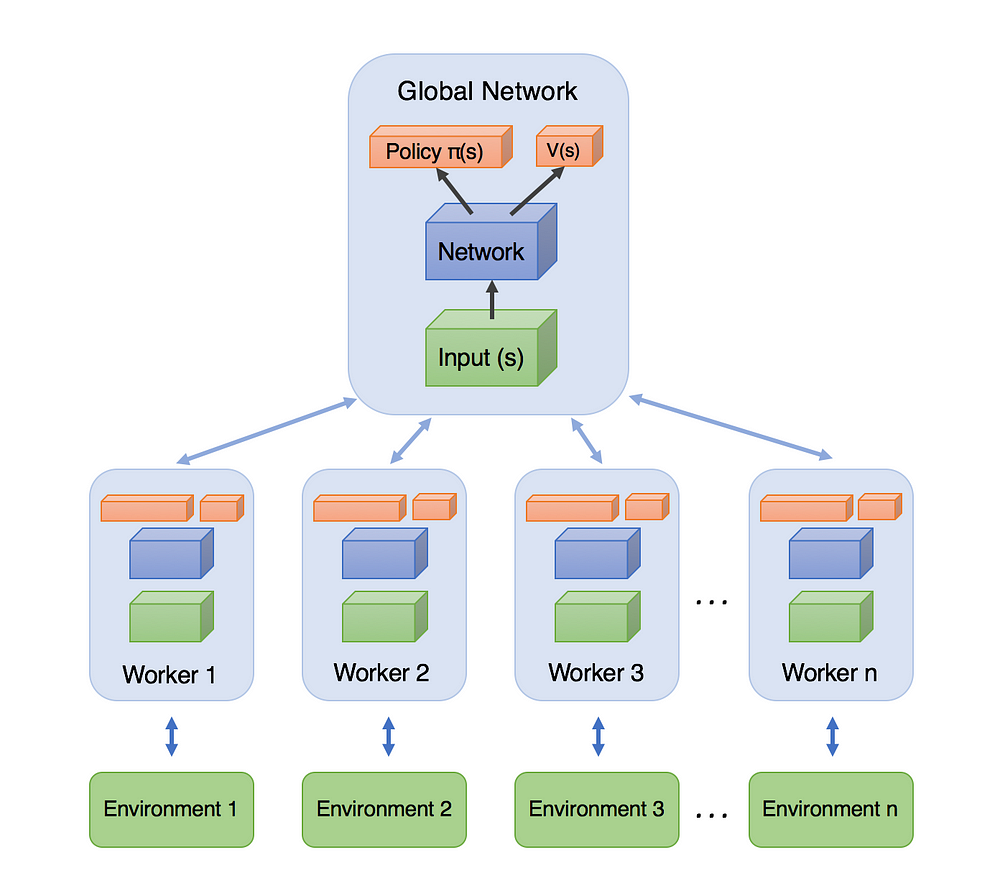
实现与流程
首先是其中的各个worker agent的训练流图:
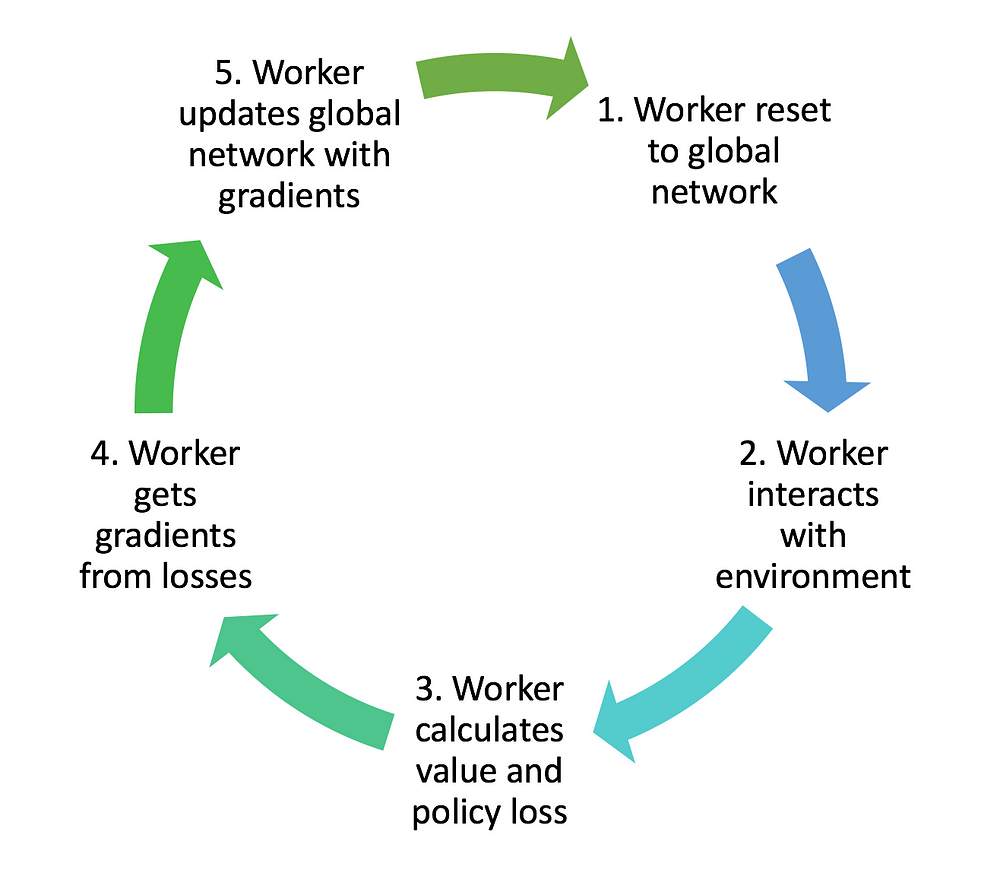 从图中很明显看到:worker是根据主网络的参数来进行重置的,然后分别各自与各自的环境交互 然后计算actor中的policy loss和critic中的value loss,进而基于损失函数获得梯度gradient,利用gradient 更新总网络 之后根据需要根据更新后总网络的参数来重置worker中的参数;
从图中很明显看到:worker是根据主网络的参数来进行重置的,然后分别各自与各自的环境交互 然后计算actor中的policy loss和critic中的value loss,进而基于损失函数获得梯度gradient,利用gradient 更新总网络 之后根据需要根据更新后总网络的参数来重置worker中的参数;
基于此 需要两个类
ACNet:顾名思义的也就是完成了对于actor-critic的建立,其中的操作包括对应actor和critic的网络的建立 和优化的各类参数,因为有着global network和各个worker的区别,于是需要基于worker中的梯度更新主网络和将主网络更新好的参数推送到各个worker的操作;Worker:关于网络我们是借助ACNet来搭建的,但这还只是agent;一个完整的RL操作,还需要与env的交互,于是这里设置一个work方法,在其中一边与env交互 一边存储其中的参数;
结构
同样的是一个global network和多个work;两者基于同样的网络结构「build_network」,但是其中需要的参数和操作不同,work需要一个sync操作「update global的参数 以及 获取global的参数」和交互的操作;
建立一个global network,得到其中的actor参数和critic的参数;其中的self.s 只是为了建立网络结构;
每个网络结构并非只是单纯的policy一个 value一个,policy的网络同样的输入 给出了两个输出:毕竟是连续的动作 使用了 Normal distribution 来选择动作, 所以在搭建神经网络的时候, actor 这边要输出动作的均值和方差. 然后放入 Normal distribution 去选择动作;计算 actor loss 的时候我们还需要使用到 critic 提供的 TD error 作为 gradient ascent 的导向.「换句话说 计算得到均值和方差后 首先要构建normal分布 才能根据action对应输出action的概率」「loss后面那个多个的熵 参考文章里面的设定」
还有就是关于以policy选择action的时候,参考doom中可以看到 这样离散的action情况 他是max来选择action,而这里是依照概率分布 来选择action;「恩 采样一个值 去掉多余的axis 只留下value」
算了 还是对着代码来说吧;
这里对于Worker中的work方法里面的也有着存储buffer的操作,但这里并不是experience replay;而只是每个worker里面经过的state和action等参数对应记录下来,然后用于更新时候的使用;可以发现:其中的存储的数值并未被打散,毕竟已经asynchronous了 各个worker之间的样本本身就是独立同分布的存在,就没必要experience replay来消除其中的相关性;
实现——ACNet
首先从ACNet开始讲起,在上面 我们已经说过 在A3C中需要一个global network和多个worker,每个worker都是一个单独的AC;同时global network和worker中的网络结构是一样的;我们需要的就是借助worker来与env进行交互然后产生数据后,生成梯度更新global network中的参数,然后再把global network中的参数迁移到worker中 完成一次更新;
于是总结上面的话 首先 我们需要将global network和worker的情况进行分开;毕竟在global network中只需要建立一个神经网络 然后等着梯度来更新网络参数就好了;而梯度的生成的loss function的建立,梯度的计算 都需要在worker里面进行建立的,此外将计算好的梯度抛出去 给global network进行更新还有接收global network中的参数进行覆盖自身 因为都会在后面的worker类的work方法中实现,于是这里都需要设置相关参数
于是我们在开始的初始化函数中:
class ACNet(object):
def __init__(self, scope, globalAC=None):
if scope == GLOBAL_NET_SCOPE:
# 在global network中我们只需要设置好输入
# 建立好网络就好了 当然 为了方便 这里的build network
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_params, self.c_params = self._build_net(scope)[-2:]
else:
# 然后对于worker中的网络 尽管神经网络的input一样
#但是为了计算actor这个策略梯度的loss 我们还是需要input action的选择 来体现策略
#同样是为了建立actor的loss 我们需要input td误差来作为gradient ascent的导向;
#恩 就是导向 发现这里是target-v,建立的loss中加上了负号 根据策略梯度的loss的描述
#「参考前面一篇文章」会朝着大的值方向上进行 也就是v会朝着和target接近的方向进行;
#actor loss中的那个熵的设置是为了鼓励探索所设置的
# 这里关于网络的建立 和对于输出的wrap在后面 build network中说;
# 对于critic的loss 就是单纯的td error的相关loss function;
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_his = tf.placeholder(tf.float32, [None, N_A], 'A')
self.v_target = tf.placeholder(tf.float32, [None, 1], 'Vtarget')
mu, sigma, self.v, self.a_params, self.c_params = self._build_net(scope)
td = tf.subtract(self.v_target, self.v, name='TD_error')
with tf.name_scope('c_loss'):
self.c_loss = tf.reduce_mean(tf.square(td))
with tf.name_scope('wrap_a_out'):
mu, sigma = mu * A_BOUND[1], sigma + 1e-4
normal_dist = tf.distributions.Normal(mu, sigma)
with tf.name_scope('a_loss'):
log_prob = normal_dist.log_prob(self.a_his)
exp_v = log_prob * tf.stop_gradient(td)
entropy = normal_dist.entropy() # encourage exploration
self.exp_v = ENTROPY_BETA * entropy + exp_v
self.a_loss = tf.reduce_mean(-self.exp_v)
#这里的选取action 因为action为连续的值 于是就是采样后在action space中找到对应的值
with tf.name_scope('choose_a'): # use local params to choose action
self.A = tf.clip_by_value(tf.squeeze(normal_dist.sample(1), axis=0), A_BOUND[0], A_BOUND[1])
#计算出来actor和critic对应的gradient
with tf.name_scope('local_grad'):
self.a_grads = tf.gradients(self.a_loss, self.a_params)
self.c_grads = tf.gradients(self.c_loss, self.c_params)
with tf.name_scope('sync'):
with tf.name_scope('pull'):
#使用global network中的参数覆盖worker中的
#用在:使用了worker的梯度更新了global network参数后 就紧接着覆盖
#使用的是.assign操作
self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.a_params, globalAC.a_params)]
self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.c_params, globalAC.c_params)]
with tf.name_scope('push'):
# 这里的OPT_A和OPT_C代指优化器 或者说优化方法,
#然后这里的就是将worker中的梯度拿来更新global的参数
self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params))
self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params))
紧接着就是重要的建立网络的函数,这里将actor和critic的NN建立函数放在了一个函数里面实现,同时 因为这里对应的是连续action,于是这里的输出层包含一个mu和sigma 合起来就是一个Normal distribution 来选择动作;再回头看看上面的初始化函数,是不是对这个mu和sigma的输出进行了wrap 比如建立actor loss的时候,就是基于此建立分布 然后log;「毕竟不还是要获得一个action对应的probability吗」
然后就是mu和sigma的输出 经过同样的input layer和hidden layer后的各自输出的;
critic中的就是输出v值;
这里顺手用slim弄了下 没测试效果;
def _build_net(self, scope):
w_init = tf.random_normal_initializer(0., .1)
with tf.variable_scope('actor'):
l_a = tf.layers.dense(self.s, 200, tf.nn.relu6, kernel_initializer=w_init, name='la')
mu = tf.layers.dense(l_a, N_A, tf.nn.tanh, kernel_initializer=w_init, name='mu')
sigma = tf.layers.dense(l_a, N_A, tf.nn.softplus, kernel_initializer=w_init, name='sigma')
#l_a=slim.fully_connected(self.s,200,activation_fn=tf.nn.relu6,weights_initializer=w_init)
#mu=slim.fully_connected(l_a,N_A,activation_fn=tf.nn.tanh,weights_initializer=w_init)
#sigma=slim.fully_connected(l_a,N_A,activation_fn=tf.nn.softplus,weights_initializer=w_init)
with tf.variable_scope('critic'):
l_c = tf.layers.dense(self.s, 100, tf.nn.relu6, kernel_initializer=w_init, name='lc')
v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # state value
#l_c=slim.fully_connected(self.s,100,activation_fn=tf.nn.relu6,weights_initializer=w_init)
#v=slim.fully_connected(l_c,1,activation_fn=tf.nn.relu6,weights_initializer=w_init)
a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
return mu, sigma, v, a_params, c_params
另外还有一些辅助函数 主要就是将梯度抛到global中进行更新的;global覆盖worker的;选择action的;
def update_global(self, feed_dict): # run by a local
SESS.run([self.update_a_op, self.update_c_op], feed_dict) # local grads applies to global net
def pull_global(self): # run by a local
SESS.run([self.pull_a_params_op, self.pull_c_params_op])
def choose_action(self, s): # run by a local
s = s[np.newaxis, :]
return SESS.run(self.A, {self.s: s})[0]
实现——Worker
在完成对于总体的ACNet的结构后,需要塑造worker单独的一个类,虽然agent相关的参数再AC里面已经叙述完毕,但是包含env在内,在worker类里面依旧需要再建一个函数 方便后面的操作 ;
GAME = 'Pendulum-v0'
GLOBAL_RUNNING_R = []
GLOBAL_EP = 0
MAX_EP_STEP = 200
MAX_GLOBAL_EP = 2000
UPDATE_GLOBAL_ITER = 10
class Worker():
def __init__(self,name,globalAC):
self.env=gym.make(GAME).unwrapped
self.name=name
self.AC=ACNet(name,globalAC)
def work(self):
global GLOBAL_RUNNING_R, GLOBAL_EP
total_step=1
buffer_s,buffer_a,buffer_r=[],[],[]
# s, a, r 的缓存, 用于 n_steps 更新
while not COORD.should_stop() and GLOBAL_EP < MAX_GLOBAL_EP:
s=self.env.reset()
ep_r=0
for ep_t in range(MAX_EP_STEP):
a=self.AC.choose_action(s)
s_,r,done,info=self.env.step(a)
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append(r)
# 每 UPDATE_GLOBAL_ITER 步 或者回合完了, 进行 sync 操作
if total_step % UPDATE_GLOBAL_ITER == 0 or done:
#计算TD error需要 next state的value
if done:
v_s=0
else:
v_s_=SESS.run(self.AC.v, {self.AC.s: s_[np.newaxis, :]})[0, 0]
buffer_v_target = [] # 下 state value 的缓存, 用于算 TD
for r in buffer_r[::-1]:
v_s_=r+GAMMA*v_s_
#先倒叙 然后从最后一位开始按照公式依次计算v_s_「最后一位只有一个GAMMA 倒数2 要两个」
buffer_v_target.append(v_s_)#计算完成全部后 再反转
buffer_v_target.reverse()
buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.vstack(buffer_a), np.vstack(buffer_v_target)
feed_dict = {
self.AC.s: buffer_s,
self.AC.a_his: buffer_a,
self.AC.v_target: buffer_v_target,
}
self.AC.update_global(feed_dict) # 推送更新去 globalAC
buffer_s, buffer_a, buffer_r = [], [], [] # 清空缓存
self.AC.pull_global() # 获取 globalAC 的最新参数
s=s_
if done:
GLOBAL_EP += 1 # 加一回合
break # 结束这回合
实现——整体实现
最后就整体实现的函数了 emmm 感觉没什么好说的了;
OUTPUT_GRAPH = True
LOG_DIR = './log'
#然后就是整体的函数了
if __name__=="__main__":
SESS=tf.Session()
with tf.device("/cpu:0"):
OPT_A= tf.train.RMSPropOptimizer(LR_A, name='RMSPropA')
OPT_C = tf.train.RMSPropOptimizer(LR_C, name='RMSPropC')#选择的优化器
GLOBAL_AC = ACNet(GLOBAL_NET_SCOPE) # we only need its params
# 建立 Global AC
workers=[]
for i in range(N_WORKERS): # 创建 worker, 之后在并行
workers.append(Worker(GLOBAL_AC)) # 每个 worker 都有共享这个 global AC
COORD = tf.train.Coordinator() # Tensorflow 用于并行的工具
SESS.run(tf.global_variables_initializer())
if OUTPUT_GRAPH:
if os.path.exists(LOG_DIR):
shutil.rmtree(LOG_DIR)#
tf.summary.FileWriter(LOG_DIR, SESS.graph)
#判断是否存在log文件夹 若存在则删除 remove 再指定一个文件用来保存图。
worker_threads = []
for worker in workers:
job = lambda: worker.work()
t = threading.Thread(target=job) # 添加一个工作线程
t.start()
worker_threads.append(t)
COORD.join(worker_threads) # tf 的线程调度
plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R)
plt.xlabel('step')
plt.ylabel('Total moving reward')
plt.show()