前言
上周所看的有关目标检测的一些东西,之前面试的时候也被问道过有关目标检测的问题 了解的不多 于是上周的时候,将其中有关候选框的DL方法进行了一波了解和学习,做的一些总结性的知识的东西,代码和使用的话 更多的还是用的Google官方公布的一个基于tensorflow的实现;
碎碎念时间:了解了一波才发现blog文章上面的图片最好的分辨率原来是1900x870 或者说高为1080的也还可以,发现现在每次写blog之前 花更多的时间可能就是这里的header-img的选取和处理了吧hhhh
首先是Tensorflow Object Detection API安装
就像上面所说的,这里更多的关注的是怎么样用的,于是这里也就直接采用的Tensorflow Object Detection API安装,对于其介绍就不在赘述,这里只说些自己遇到的一些问题和解决; 流程大致和https://blog.csdn.net/RobinTomps/article/details/78115628 一模一样,「对于protobuf的使用就是,下载 protoc-3.4.0-win32.zip 然后把bin里面的exe文件移动到C:\Windows\System32就可以了 当然你也可以加到系统路径 」 但是啊 会出现一个问题就是:你的tensorflow版本的问题,最新的https://github.com/tensorflow/models 里面依赖的tensorflow不用问 肯定是最新的,起码也是1.9的,看了看自己的1.4版本,想着怎么解决吧,点进入release版 下载 emmm没有research文件夹 emmmm 这还玩个毛线啊,Object Detection都没有 然后点进去branches里面 果然有历史版本,然后选择和1.4靠近的版本 毕竟1.4本身没有research文件夹,所以就选择附近的版本,下载后 继续上面csdn的教程;
什么是目标检测
然后就开始说关于目标检测的一些笔记和总结了; 首先 目标检测属于计算机视觉的一部分,其可以将图像或者视频中的目标与不感兴趣的部分区分开,判断是否存在目标,若存在目标则确定目标的位置.常见研究领域包括:目标跟踪,视频监控,信息安全,自动驾驶,图像检索,医学图像分析,网络数据挖掘,无人机导航,遥感图像分析,国防系统等。
如今,目标检测与识别的研究方法主要由两大类:
- 基于传统图像处理和机器学习算法的目标检测与识别方法
- 基于深度学习的目标检测与识别方法
如果对于目标检测是什么以及能做什么进行思考的话,那么就定义来说其针对一幅场景(图片)中找出目标,需要解决检测(where)和识别(what)两个过程。可以看到这里需要解决两个问题:一个是针对待检测区域的判定 另外一个就是选定候选对于其的提取与识别.因而目标检测大体框架主要包括:
- 首先建立从场景中提取候选区的模型
- 然后识别候选区的分类模型
- 最后精调分类模型的参数和有效候选框的位置精修
传统方法的目标检测
上面也说过 对于目标提取需要解决检测(where)和识别(what)两个过程;毕竟 1、物体可以出现在图片的任何地方,并且其尺寸变化范围很大。2、摆放物体的角度,姿态不定。3、物体还可以是多个类别。
如果只是直接的针对某种物体整体进行识别,那么为了描述这个个体就需要考虑到 该物体全部的姿态和变形 不然微微的形变就会导致算法认为识别的物体不是他;「表格式和值函数近似方法也是从这个角度来思考的」 因而我们使用一系列特征来表示这个物体,只要识别出来特征这些关键的点 那么就可以认为识别出来这个物体; 因而说 传统的图像处理方法和深度学习的处理方法,两者的区别 其实更多的也就是在于这里的特征提取的方式,其流程大致都可以分为:
- 基于 例如穷举法的方式 找出所有物体可能出现的区域;
- 对于这些区域进行提取特征;
- 在使用图像识别方法进行分类;
- 非极大值抑制来输出结果「类似于最大池化 只关注于最重要的部分 其他的细枝末节不关注」
传统的方法 其实也就是采用传统的特征提取方法如:尺度不变特征变换「Scale-Invariant Feature Transform」(SIFT)、加速鲁棒特征「Speeded-Up Robust Features」(SURE)Haar特征、方向梯度直方图「Histogram of Ori- ented Gradient」「HOG」、Strip特征等等; 分类的方法其实更多的也还是ML那些分类算法 从KNN到SVM RF等;
传统方法存在的问题
因为手动制作的特征存在多种问题:一方面手工制作的特征属于低层特征,对于目标的表征能力不足;同时 手工制作的特征可分性较差 导致分类的错误率较高;最后 手工制作的特征具有针对性 很难选择单一特征用于多目标的检测,如Haar特征用于人脸检测,HOG特征用于行人检测。Strip特征主要用于车辆检测;
深度学习方法的目标检测
而CNN本身的特性, 提取出来的特征就很好的解决这一问题;
- 局部特征作为卷积的核心思想,借助于相同的一组参数,针对输入数据的一部分带来的是相同的映射关系,提取的是相同类型的特征;
- 平移等变性:平移等变性保证 当输入发生一定的如:平移 旋转 缩放等简单变化后 依旧能完成对于图像的识别。「关注特征是否出现 而不是它的具体位置」
针对上面所提到的传统方法的问题,DL有针对性的进行了解决。首先CNN通常对于输入图像进行交替的卷积操作和池化操作,特征经过多次的非线性变换 导致从底层特征逐渐抽象成为高级特征 进而使提取出来的特征对于目标有真很强的表达能力; 再者 对于一个CNN其中融入了特征提取特征选取特征分类功能 采用端到端的训练方式,让特征具有一定的可分性; 同时训练出来的CNN针对目标的特征提取 取决于训练数据,所以采用多个目标类别的样本后 提取出来的特征就不再是只针对于特定目标的目标类别; 因而卷积神经网络的方法 成功解决了传统目标检测方法中的三点不足之处; 当然 目前可以将现有的基于深度学习的目标检测与识别算法大致分为以下三大类:
- 基于区域建议的目标检测与识别算法,如R-CNN, Fast-R-CNN, Faster-R-CNN;
- 基于回归的目标检测与识别算法,如YOLO, SSD;「和上面的方法的区别主要在于:前者先生成候选框 再识别物体;后者是没有中间的区域检出过程,直接从图片获得预测结果」
- 基于搜索的目标检测与识别算法,如基于视觉注意的AttentionNet,基于强化学习的算法;
对于这里基于RL的方法还是有点兴趣的,简单看了看:基于强化学习的目标检测方法,将目标检测的过程抽象为时序的、不断产生决策动作的Markov过程。相比于直接得到目标位置方式,基于强化学习的目标检测方法中定位智能体不断地做出动作决策,迭代地定位到待检测目标。如下图所示,智能体不断地调整观察窗口的大小/横纵比、移动观察窗口,最终定位到目标所在区域。
 「来自于Active object localization with deep reinforcement learning」
「来自于Active object localization with deep reinforcement learning」
这里不是我们的重点 我们这里主要是为了介绍第一种基于候选框的方法的目标检测方法;就思路的话和之前的传统方法类似,步骤如下:
- 首先使用选择性搜索算法(Selective Search,SS)、Bing、EdgeBoxes这些目标候选区域生成算法生成一系列候选目标区域;
- 然后通过深度神经网络提取目标候选区域的特征;
- 最后用这些特征进行分类,以及目标真实边界的回归;
R-CNN
首先是第一种方法R-CNN,作为第一种将DL用于目标检测算法,可以说后面的DL类目标检测方法都是在其基础上的;
参考传统方法,这里手工特征提取方法被改变成为了CNN提取特征,参考下图: 1) 接收一个图像, 使用Selective Search选择大约2000个从上到下的类无关的候选区域(proposal)
1) 接收一个图像, 使用Selective Search选择大约2000个从上到下的类无关的候选区域(proposal)
选择搜索算法的观点,就是针对整体的区域集R 基于子区域之间的相似性(颜色、纹理、大小等等)进行区域合并,不断的进行区域迭代合并。毕竟物体可能存在的区域肯定有着某些相似性和连续的区域 进而完成合并 具体到SS里面 就是首先需要计算全部的区域集每个相邻区域之间的相似度「两块区域之间的相似度」集合为R,找出其中最大的那个,也就是找到了相似度最大的那两块区域,进而移除R中其他和这两块区域相关的子集「a和a1 a2相邻,a和a1相似度更高 那么a和a2的就没有意义了」,然后重新计算相似度 不断循环;
2) 将提取出来的候选区域转换为统一大小的图片(拉升/压缩等方法), 使用CNN模型提取每一个候选区域的固定长度的特征.
3) 使用特定类别的线性SVM分类器对每一个候选区域进行分类.
4) Bounding Box回归.「画框」
Selective Search对算法的贡献:此前,在一些传统的目标识别算法中,使用的是滑动窗口进行候选区提取,这样会导致在一章图片中会产生高达百万个候选区,而在R-CNN中,使用选择性搜索算法,每次提取的候选区大概只有1k到2k可能包含物体的区域。
使用深度CNN提取建议区域的特征时,需要注意的是,有些网络对输入图片的大小有要求,如Alex-net要求输入的图片尺寸为227像素*227像素的大小。因此,由SS提取得到的候选区的尺寸大小不一,需要在输入神经网络之前调整大小。通过深度CNN提取特征后,每个目标候选区域相应得到一个4096维的特征向量。
以上得到了每个候选区域的特征向量,接下来使用SVM分类器对特征进行分类。
相对与传统的方法,R-CNN的主要优势有: - 使用深度学习方法提取深度特征,而不是使用人为设计,因此提高了任务精度。 - 采用区域建议提取可能目标,而不是使用滑动窗口的方式取检测目标,这样减少了不必要的候选区。 - 加入了边界回归的策略来进一步提高检测精度
尽管结构和传统方法类似,但是得益于CNN优秀的特征提取能力 还是在公共数据集上的准确率有着突破性的进展,如在PASCAL VOC的准确率从35.1%提升到了53.7%,但是R-CNN也有一定的局限性。目标候选区的重叠使得CNN特征提取的计算中有着很大的冗余,着很大程度上限制了检测速度。针对这个缺点将R-CNN升级为Fast-R-CNN。
不足
- 整个模型分为多个步骤,包括Selective Search提取候选区,训练CNN提取深度特征,训练SVM进行分类没训练边框回归器。
- 测试时间长,由于每张图片要处理大量的目标候选框「意思是每次提取出来候选框后 就需要通过一次CNN」
- 训练时所需空间大,花费时间多,R-CNN训练时处理每一张图片全部resize到227*227分辨率的图像候选框(为了避免图像扭曲严重,中间可以采取一些技巧减少图像扭曲),并输入网络中,这使得处理每一章图片所使用的空间大,同时整个模型需要训练CNN, SVM分类器,以及目标边框回归器,从而导致训练时间花费很多。
Fast-R-CNN
这里首先涉及一个SPP Net的概念;
其功能就是让CNN可以接受任意尺寸的输入,毕竟一般来说对于CNN来说只能接受固定大小的输入,经过一步步的计算 最终得到一个固定尺寸的结果;
而SPP Net:
① 结合金字塔的思想, 实现了实现了CNNs的多尺寸输入. 解决了因为CNNs对输入的格式要求而进行的预处理(如crop,warp等)操作造成的数据信息的丢失问题.
② 只对原图进行一次卷积操作.
对于其实现参考下图:
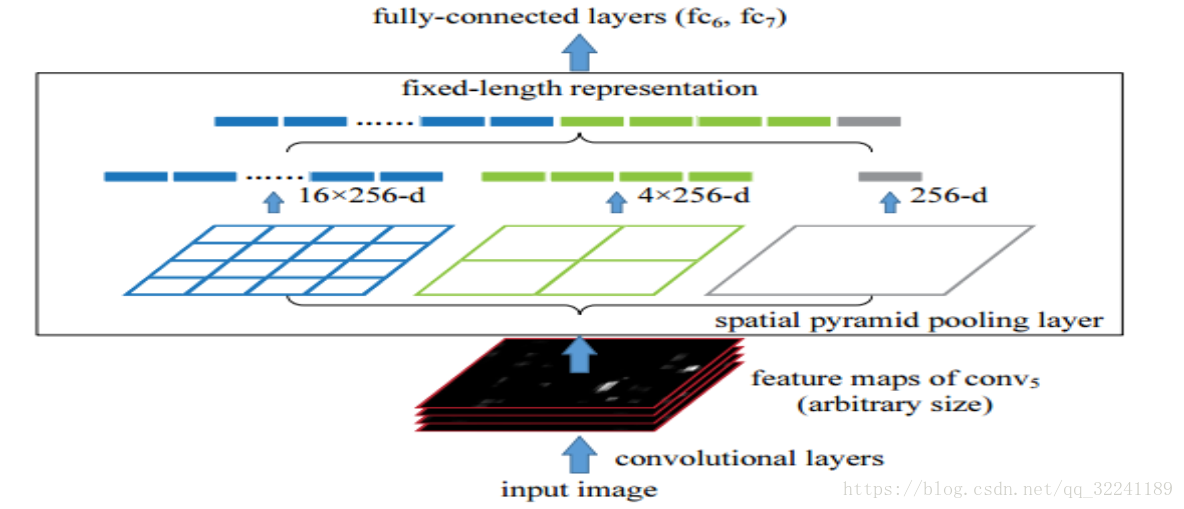
如图 针对一个60*40*256的特征图 采用三层金字塔池化层pooling,如论文中采用(1,4,16),然后按照层次对这个特征图feature A进行分别处理(用代码实现就是for(1,2,3层)),也就是在第一层对这个特征图feature A整个特征图进行池化(池化又分为:最大池化,平均池化,随机池化),论文中使用的是最大池化,得到1个特征。
第二层先将这个特征图feature A切分为4个(20,30)的小的特征图,然后使用对应的大小的池化核对其进行池化得到4个特征,
第三层先将这个特征图feature A切分为16个(10,15)的小的特征图,然后使用对应大小的池化核对其进行池化得到16个特征.
最后将这1+4+16=21个特征输入到全连接层,进行权重计算;「当不能整除 取整」 可以看到SPP Net更多是因为采取了ROI这种池化操作,来对于卷积操作之后的feature map起到了特征识别的目的;毕竟最终得到的结果向量 只是和特征数目有关; 进而我们将这种思想运用于特征提取中:将大小不一的候选框的特征图输入ROI后,之后输出的就是一组固定长度的和特征情况有关的向量。 这样同时也会带来一个好处,在原有R-CNN先获取候选框,再进行resize,最后输入CNN卷积, 这样做效率很低「多少候选框多少次卷积」. SPP Net针对这一缺点, 提出了只进行一次原图的卷积操作, 得到整体图的feature map , 然后找到每一个候选框在feature map上对应的区域, 将这个区域作为每个候选框的卷积特征输入到SPP Net中,进行后续运算.「不需要变形和每次提取后再卷积的操作」 速度提升百倍.
Fast R-CNN主要作用是实现了对R-CNN的加速, 它在R-CNN的基础上主要有以下几个方面的改进:
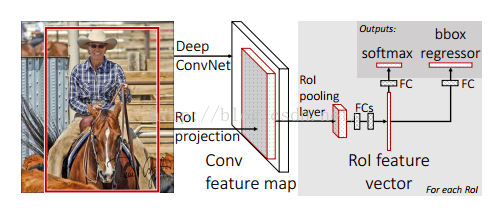
① 借鉴了SPP Net的思路, 提出了简化版的ROI池化层(没有使用金字塔), 同时加入了候选框映射的功能, 使得网络能够进行反向传播, 解决了SPP的整体网络训练的问题. ② 多任务Loss层. 1) 使用了softmax代替SVM进行多分类. 2) SmoothL1Loss取代了 Bounding Box回归.
基本工作流程 1) 接收一个图像, 使用Selective Search选择大约2000个从上到下的类无关的候选区域(proposal). 2) 对整张图片进行卷积操作提取特征, 得到feature map. 3) 找到每个候选框在feature map中的映射patch. 将patch作为每个候选框的特征输入到ROI池化层及后面的层. 4) 将提取出的候选框的特征输入到softmax分类器中进行分类.==>替换了R-CNN的SVM分类. 5) 使用SmoothL1Loss回归的方法对于候选框进一步调整位置.
Fast R-CNN的优点及其不足之处 1) 优点 融合了R-CNN和SPP Net的精髓, 并且引入了多任务损失函数 ,极大地特高了算法的效率, 使得整个网络的训练和测试变得较为简单(相对R-CNN而言). 2) 不足 没有对Selective Search进行候选区域(region proposal)的选择进行改进, 仍然不能实现真正意义上的edge-to-edge(端到端)的训练和测试. Fast R-CNN和SSPNet的区别 也只是在与前者将SVM改为了NN,具体来说就是:从ROI后 分出来两支,一支经过一个FCN 用于分类「softmax」 另一个经过一个FCN用于回归; 前者的分类 比如在图像中检测出来K类物体 那么就要有着K+1个输出,分别表示区域内为类别i的概率(K个)和 一个用于判定当前区域有无目标物体的情况; 而回归的作用是为了对输出框的校准;比如原来的框包含四个参数$(x,y,w,h)$ 其中$(x,y)$代指框左上角的坐标,然后w代表宽度 h代表高度,而实际的位置为$(x’,y’,w’,h’)$ 进而就是要学习到参数$(\frac{x’-x}{w},\frac{y’-y}{h},ln\frac{w’}{w},ln\frac{h’}{h})$ 前面两个表示和原来尺寸无关的平移量 后面两个表示和尺寸无关的所放量;
##Faster R-CNN 联合当前笔记里面的内容以及D:\文件\Fight_in_2018\随手写的代码[tensorflow的21个项目]Deep-Learning-21-Examples-master\Deep-Learning-21-Examples-master\chapter_5\Document.md 里面的介绍,知道了fast rcnn对于rcnn的改进更多但还是在于引入了ROI这样一个池化层,从而只需要进行一次卷积操作 来完成对于各个候选框其中区域的特征识别; 但 这里依旧有这问题就在于依旧需要使用提取框来选取候选区域,才能进行后续的操作,而这依旧需要花费大量的时间,因而在faster r-cnn里面对于候选框的提取 从R-CNN里面的SS改变成了一个region proposal network即RPN「R-CNN里面采用了selective search也同样是一大相比于传统方法的改进 从上百万候选区域变得只剩下1k作用 当然还是很大」
RPN
首先是网络结构 其实对于RPN的理解,重点就是在于其中引入的一个概念anchor 对其理解好了 然后再看后面的操作其实就简单了;
首先什么是anchor?其更多的还是一组大小固定的参考窗口,三种尺度「面积」{128^2,256^2,512^2}×三种长宽比{1:1,1:2,2:1}「就是面积为固定值 根据不同长宽比 体现出来对应的图像」;我们可以联系SPPNet中的理解,原来SPP里面 可以让不同尺寸的输入resize成为相同尺度的输出,而这里 其实相当于由相同尺度的输出 逆推得到不同尺寸的输入;
具体来说 参考上面的网络结构 原始图像经过第一次卷积操作得到一组原始特征图
其实对于RPN的理解,重点就是在于其中引入的一个概念anchor 对其理解好了 然后再看后面的操作其实就简单了;
首先什么是anchor?其更多的还是一组大小固定的参考窗口,三种尺度「面积」{128^2,256^2,512^2}×三种长宽比{1:1,1:2,2:1}「就是面积为固定值 根据不同长宽比 体现出来对应的图像」;我们可以联系SPPNet中的理解,原来SPP里面 可以让不同尺寸的输入resize成为相同尺度的输出,而这里 其实相当于由相同尺度的输出 逆推得到不同尺寸的输入;
具体来说 参考上面的网络结构 原始图像经过第一次卷积操作得到一组原始特征图51*39*256「第一列」,在此基础上 对于这样一组原始特征图 通过一个3x3的滑动窗口,在这个51x39的区域上进行滑动,stride=1,padding=2,这样一来,滑动得到的就是51x39个3x3的窗口。
这样的51x39个3x3的窗口 我们其实就可以看做是SPP里面已经经过操作后的最终输入,那么如果按照SPP里面的想法 我们可以推导其原来可能的输入shape 这里其实就是anchor的意义,也就是三种尺度「面积」{128^2,256^2,512^2}×三种长宽比{1:1,1:2,2:1} 共计九种可能的区域,而这可能的九种原图的中心点都是3x3的中心点「同样的 上面介绍也看到padding=2 所以全部的可能中心点也就是有着和输入特征图shape一样的个数 为51x39个」
所以总共的anchor box 就是有着51 x 39 x 9 = 17900个;
进一步的 每个 anchor box对应的proposal区域,都会输出6个参数,包含两类:每个 proposal 和 ground truth 进行比较得到的前景概率和背景概率(2个参数)(对应图上的 cls_score);由于每个 proposal 和 ground truth 位置及尺寸上的差异,从 proposal 通过平移放缩得到 ground truth 需要的4个平移放缩参数(对应图上的 bbox_pred)。「参考上面的fast r-cnn,毕竟之后的部分也就是fast r-cnn了」
 大致流程如下:
首先对于CNN输入用于识别的图片;「这里的CNN为前期共享的CNN」然后经过CNN前向传播到共享的卷积层最终层后,开始分支:一方面这里来自于共享网络层输出的特征图输入到RPN里面用于进行区域建议的得到,另外的继续前向传播 经过特有卷积层得到更高维的特征图 就像fast r-cnn里面一样;
然后RPN里面的操作 就像是上面介绍的那样:针对来自于共享卷积层输出的特征图 比如
大致流程如下:
首先对于CNN输入用于识别的图片;「这里的CNN为前期共享的CNN」然后经过CNN前向传播到共享的卷积层最终层后,开始分支:一方面这里来自于共享网络层输出的特征图输入到RPN里面用于进行区域建议的得到,另外的继续前向传播 经过特有卷积层得到更高维的特征图 就像fast r-cnn里面一样;
然后RPN里面的操作 就像是上面介绍的那样:针对来自于共享卷积层输出的特征图 比如w*h*c,有着w*h个点,然后在上参考上面 对其进行stride=1,padding=2的kernel=3x3的滑动,得到一个新的低维特征向量「当然按照上面介绍 使用这一的stride和padding参数设置 新的特征向量不发生变化 当然一般情况下肯定会相对低维一些的」,然后为这么3x3的框考虑k种可能的参考窗口「上面设置为9」,于是对于一个W×H的特征图,就会产生W×H×k个区域建议;
进而 对于上面生产的低维特征向量输入两个并行连接的卷积层2:reg窗口回归层【位置精修】和cls窗口分类层,分别用于回归区域建议产生bounding-box【超出图像边界的裁剪到图像边缘位置】和对区域建议是否为前景或背景打分,这里由于每个滑窗位置产生k个区域建议,所以reg层有4k个输出来编码【平移缩放参数】k个区域建议的坐标,cls层有2k个得分估计k个区域建议为前景或者背景的概率;
而这里 获取概率的意义 也是对于区域的分进行非极大值抑制「阈值为0.7」 选取其中top-N「原文为300」的区域 建议给ROI池化层 用于后面的fast r-cnn;「也就是完成了候选框的选取工作」
至于fast r-cnn所干的就是基于RPN里面的得到的候选区域 以及 之前共享层再经过特有层的高维特征图 输入ROI池化层,提取对应区域的特征情况,再进而经过FCN 得到最终的分类得分以及回归后的bounding-box。
后面的都可以参考fast r-cnn了
「参考这里来看 https://cloud.tencent.com/developer/article/1016692」