前言
这一周把RNN相关的东西给看了一下,毕竟现阶段DL的两大领域:CV和NLP。CNN至少都要有所了解,而NLP还是看得少一点,于是这周将其中相关的东西给好好看了一波,没有太多更深的东西 都比较基础,只是自己总结复述一波。顺带上周把目标检测看了一波也做了些总结,之后再放上来这里吧;
碎碎念时间:以上那行字是一个点之前就写完的,结果在回顾之前的文章的时候,就着:标题的字体颜色应该如何修改陷入沉思,纯白颜色的标题搭配上倒霉催的没注意放上去一群亮色的;思考了一波解决方法有两种:要么改字要么改图,在怼了半个点的Jekyll又看了好久的HTML语法,最后还是放弃了 如何修改字体这种方法;忽然发现 还是改图更简单些 那么改吧 给相关图加上蒙版,顺带还不死心的找了一波该如何自动的给加上去,最后老老实实用PS一个个弄上去吧还是;
RNN的前向和后向过程
RNN前向
其实 把RNN和普通的NN放在一起来看其实是很类似的,毕竟都是神经网络 但是不同之处在于:RNN里面其影响输出的不再是单独的输入和对应权值了,而且还需要考虑之前的状态情况 也就是来自于之前的输入; 同时就像是RNN解决的问题一样:序列数据的输入,也就是说前后的数据之间是有着关系的,换句话说 某一时刻所做出决策或者映射结果不再是只是因为当前的输入得到的,而是还需要考虑之前的情况,因而这里我们引入一个新的变量来描述 之前状态情况和当前的输入 共同作用得到当前时刻下最终的输出; 即$h_t=f(Ux_t+Wh_{t-1}+b)$ ,进而在此基础上 在设置新的权值得到正常的输出$y_t=softmax(Vh_t+c)$, 前面的U和W等参数更多的还是相当于设置:当前时刻输入和之前状态情况所占的比重,这里的V等才是真正的用于建立映射; 同样的反向传播的时候 显然的对于V和c,直接建立就好,但是如果设置U和W,那么就会涉及$h_t$ 先对于$h_t$进行求偏导倒是,显然对于其求偏导 包含两部分 一个是从$y_t$直接得到的,另外一个就是从$y_{t+1}$经过$h_{t+1}$得到的;
RNN反向
来自于之前的一般比较 所以可能参数描述不太一样,但思路是一个;
首先要知道RNN的前向传播,有:$a^{(t)}=b+Wh^{(t-1)}+Ux^{(t)}$;$h^{(t)}=tanh(a^{(t)})$ ;$o^{(t)}=Vh^{(t)}+c$ ; $\hat{y}_t=softmax(o^{(t0})$
RNN中的损失函数来自于不同时间步的损失函数的累加,也就是$L=\sum_t L^{(t)}$ ;这样计算c和V的梯度还是比较简单的有:
$\frac{\partial L}{\partial c} = \sum\limits_{t=1}^{\tau}\frac{\partial L^{(t)}}{\partial c} = \sum\limits_{t=1}^{\tau}\frac{\partial L^{(t)}}{\partial o^{(t)}} \frac{\partial o^{(t)}}{\partial c} = \sum\limits_{t=1}^{\tau}\hat{y}^{(t)} - y^{(t)}$
「emmm 就是这种如同DNN一样 直接链式法则的意思」
同理:$\frac{\partial L}{\partial V} =\sum\limits_{t=1}^{\tau}\frac{\partial L^{(t)}}{\partial V} = \sum\limits_{t=1}^{\tau}\frac{\partial L^{(t)}}{\partial o^{(t)}} \frac{\partial o^{(t)}}{\partial V} = \sum\limits_{t=1}^{\tau}(\hat{y}^{(t)} - y^{(t)}) (h^{(t)})^T$
但对于W,U,b 来说就很麻烦了,毕竟参考上面的前向传播的公式知道,其需要基于$h(t)$ 才能进行计算;因而需要$\frac{\partial L}{\partial h(t)} $,但是正常的有关h(t)的计算梯度应该包含两部分:当前位置的梯度损失和下一时刻的梯度损失,也就是说:反向传播时,在在某一序列位置t的梯度损失由当前位置的输出对应的梯度损失和序列索引位置 t+1时的梯度损失两部分共同决定。
于是我们得到$\delta^{(t)} =\frac{\partial L}{\partial o^{(t)}} \frac{\partial o^{(t)}}{\partial h^{(t)}} + \frac{\partial L}{\partial h^{(t+1)}}\frac{\partial h^{(t+1)}}{\partial h^{(t)}} $
$=\frac{\partial L}{\partial o^{(t)}} \frac{\partial o^{(t)}}{\partial h^{(t)}} + \frac{\partial L}{\partial h^{(t+1)}}\frac{\partial h^{(t+1)}}{\partial a^{(t+1)}}\frac{\partial a^{(t+1)}}{\partial h^{(t)}}$
$= V^T(\hat{y}^{(t)} - y^{(t)}) + W^T\delta^{(t+1)}diag(1-(h^{(t+1)})^2)$
可以看到 前面一项是:基于当前项求取关于h(t)的梯度;后面一项就是:基于下一时刻h(t+1)来求取h(t)梯度;显然从h(t+1)到h(t)除了相关的权值之外,需要经过激活函数tanh;
一些流程的介绍
当然此外还有一定的变形 比如用于:从图像输出文字 的问题,这个时候显然输入不在是序列数据,但是需要输出的还是序列数据 那么RNN就会变形成为“1 VS N”的结构,其实也还是类似的操作,但是不同的是这时候就没有$X_t$了,只剩下X 同样公式也就变成了$h_t=f(Ux+Wh_{t-1}+b)$和$y_t=softmax(Vh_t+c)$,「可以看到输入不在随着时间而变化 也就是说不再是时序数据」当然从公式来看图应该是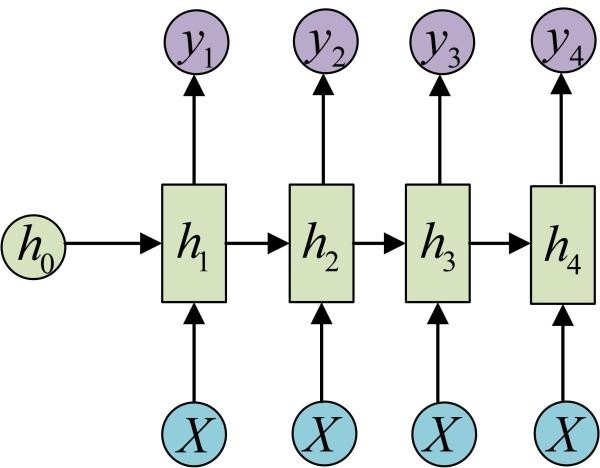
此外还有类似的形式如: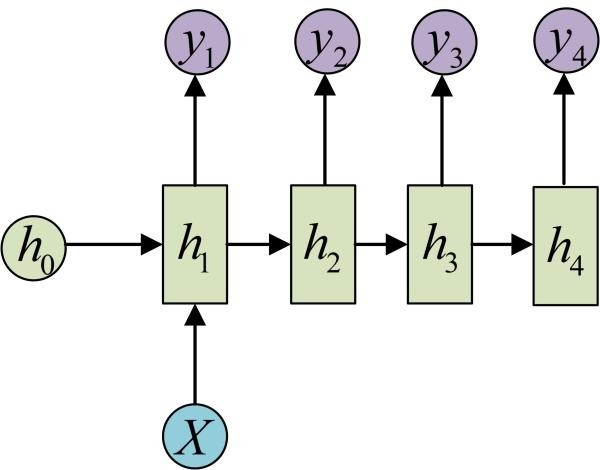
LSTM
在上面其实也提到过 对于RNN的反向传播的计算,肯定会包含对于每一部梯度的联乘,梯度爆炸和梯度消失的原因也都是来自于这,显然也就不适合处理时序较长的问题 无法处理「长程依赖」问题,也就无法学到序列中蕴含的间隔较长的规律,这时候就出现了一个新的对于RNN的改进版:LSTM;
从名字来说 翻译过来就是长短期记忆网络;我们都知道 在RNN里面再计算隐函数的时候 有$h_t=f(Ux_t+Wh_{t-1}+b)$ 这里的f一般也就是代指着tanh激活函数,显然可以从中看到 主要考虑到之前的隐函数信息和当前时刻的外界输入信息,而LSTM在此基础上又增加了一些部分,除了都有的$h_t$之外又增加了$C_t$这个概念,因此每个隐函数输出就不只是有$h_t$ 还有着$C_t$,两者的图如下:
 和
和
### LSTM里面的改进点
在后者的LSTM里面每个隐函数单元里面,水平线代指着这里引入的新参数:内部记忆状态$C_t$,显然从图中可知 其来历是来自于上一步的$C_{t-1}$ 但却不是照搬之前的$C_{t-1}$,因而这里引入了一个新的概念:遗忘门 用于控制遗忘掉$C_{t-1}$的哪些部分,如下图:
 这里的$\sigma$ 也就是所说的sigmoid激活函数,引入其中的输入包含两部分:之前的隐函数和当前的输入。我们都知道sigmoid的作用有着可以将输入映射到0-1之间的作用,经过遗忘门的权值$W_f$和两种输入$[h_{t-1},x_t]$相乘 得到一个最终和$C_{t-1}$形状相同的矩阵,矩阵和$C_{t-1}$逐点相乘。显然$f_t=\sigma(W_f [h_{t-1},x_t]+b_f )$越接近0的就是越容易被遗忘的。「原有的状态情况」
只是遗忘肯定不行,还需要保证LSTM还能记住多少新东西,也就是记忆门 或者说输入门:控制当前计算的新状态以多大的程度更新到记忆状态中:
这里的$\sigma$ 也就是所说的sigmoid激活函数,引入其中的输入包含两部分:之前的隐函数和当前的输入。我们都知道sigmoid的作用有着可以将输入映射到0-1之间的作用,经过遗忘门的权值$W_f$和两种输入$[h_{t-1},x_t]$相乘 得到一个最终和$C_{t-1}$形状相同的矩阵,矩阵和$C_{t-1}$逐点相乘。显然$f_t=\sigma(W_f [h_{t-1},x_t]+b_f )$越接近0的就是越容易被遗忘的。「原有的状态情况」
只是遗忘肯定不行,还需要保证LSTM还能记住多少新东西,也就是记忆门 或者说输入门:控制当前计算的新状态以多大的程度更新到记忆状态中: 从图中可用知道,其输入依旧是$x_t$和$h_{t-1}$,但输出包含两部分:一个是$i_t$和之前遗忘门里面的$f_t$一样经过sigmoid激活函数,另外一个是经过tanh激活函数的「虽然都类似 看起来只是激活函数的不同,但显然都有着不同的权值」,然后判断多大程度的该被记住的方式 也就是让$\tilde{C_t}$和$i_t$逐点相乘;「产生新的状态情况」
进而说当前“记忆状态 $C_t$”间的状态转移由输入门和遗忘门共同决定:
从图中可用知道,其输入依旧是$x_t$和$h_{t-1}$,但输出包含两部分:一个是$i_t$和之前遗忘门里面的$f_t$一样经过sigmoid激活函数,另外一个是经过tanh激活函数的「虽然都类似 看起来只是激活函数的不同,但显然都有着不同的权值」,然后判断多大程度的该被记住的方式 也就是让$\tilde{C_t}$和$i_t$逐点相乘;「产生新的状态情况」
进而说当前“记忆状态 $C_t$”间的状态转移由输入门和遗忘门共同决定:

在完成对于内部状态$C_t$的确定之后,当前隐函数最终的输出,其实还涉及一个输出门的概念,输出门也就是在当前的内部状态$C_t$的基础上,对于其进行tanh激活函数,然后同样的使用sigmoid激活函数进行设置计算控制当前的输出有多大程度取决于当前的记忆状态
因而完整的LSTM公示如下:

其余在:https://github.com/imhuay/Algorithm_Interview_Notes-Chinese/blob/master/A-%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/B-%E4%B8%93%E9%A2%98-RNN.md 包括一些问题
RNN实现相关
然后就是考虑实现了,这里介绍的是Char RNN这样一个结构,作为一个标准的 N VS N的结构,其输入是N个字母 基于此预测之后N个字母的概率,也就是用已经输入字母来预测下一个字母的概率,如 针对一个英文句子:「Hello!」 输入序列为{H,e,l,l} 输出序列是{e,l,l,o} 可以看到其序列等长;
测试的时候 用于生成序列的方法也就是:选定一个起始字符$x_1$,使用训练好的模型来得到生成下一字符的概率以此来得到新的字符数出,再将此字符作为下一步的$x_2$输入模型,生成下一个字符,以此类推;「从而可以生成任何长度的文字」
当然 本质上就是个多分类问题;针对字母来说 就是个one-hot形式的26分类,每一个维度上的数字代表对应字母的概率;「输入是26维度的one-hot形式,输出也是一样的26维度」
但实际上 每次只输入一个字母效果太慢,实际上是输入一个单词,毕竟一个个字母的输入 每个字母都需要one-hot形式 这shape会有多大啊;同时硬性的使用one-hot形式也忽视了单词之间的关联性,具体意思就是如cat和dog,关系就不是那么密切,而cat和computer因为有着相同的字母 应该有着关联性,进而说对其解决就是使用word2vec;比如针对一个10000词的词表,那么如果使用one-hot的形式,形成的向量也就是(10000,)的形式了,就像上面所说的one-hot的形式完全平等的看待了全部的单词,而忽视了单词之间本来具有的联系性 ,因而如果使用word2vec的方法学习到一个映射有$vector=f(word)$,vector所需要的维度相比于上面的词表也要维度少得多,比如一个256维度的向量表达一整个单词 如computer,显然所需要的维度大大减少,同时之间的映射也考虑到了单词之间的关系;
而汉字的话也一样,对于每个字都使用一个向量形式表达。具体实现的话 就是在输入的时候加入一层embedding层,因而将汉字转化为较为稠密的表示 这里的稠密对应的是one-hot这样的稀疏表示,借助于embedding层 将单个汉字映射到一个较为稠密的空间。「相比于原有单独的one-hot形式」
tensorflow里面的RNN相关
两个基本子类
至于RNN里面常说的:一步「输入上一步的隐层信息和当前的输入信息 进而计算当前步的输出和隐层信息」,而建立这个一步 所使用的就是tf.nn.rnn_cell,那么我们首先 就看其使用;
首先要注意的是rnn_cell作为抽象类并不能实例化,因而基于其子类的BasicRNNCell和BasicLSTMCell来使用,如果翻看源代码的话 看介绍的话可以知道 任何RNNCell都需要完成一个.call()的类方法,其实也就是用来实现RNN的单步计算,形如(output, next_state) = call(input, state);
可以看到 这和CNN就不一样了,在CNN里面 直接输入就好,但在RNN的使用时候,我们需要进行调用call方法;具体的来说 初始输入状态为x_1,而设置的初始隐层状态为h_0,那么就有着(output_1,h_1)=cell.call(x_1,h_0),同样的 使用x_2和h_1,我们可以计算出来
RNNCell另外还有两个类属性state_size和output_size,这里我们先捋一下整个流程:一方面我们往往使用batch的形式输入数据,于是输入有着(batch_size,input_size),调用call方法输出两种数据:一种是隐层状态有着(batch_size,state_size) 另外的就是输出(batch_size,output_size);
反映到tensorflow,形如:
import tensorflow as tf
input_data=tf.placeholder(tf.float32,shape=(100,64))
model=tf.nn.rnn_cell.BasicLSTMCell(num_units=128)
h_0=model.zero_state(100,tf.float32)
output_1,h_1=model.call(input_data,h_0)
>>> output
<tf.Tensor 'mul_2:0' shape=(100, 128) dtype=float32>
>>> h1
LSTMStateTuple(c=<tf.Tensor 'add_1:0' shape=(100, 128) dtype=float32>, h=<tf.Tensor 'mul_2:0' shape=(100, 128) dtype=float32>)
>>> h1.h
<tf.Tensor 'mul_2:0' shape=(100, 128) dtype=float32>
>>> h1.c
<tf.Tensor 'add_1:0' shape=(100, 128) dtype=float32>
RNN里面的多层堆叠
以上 包括使用方法等都进行了展示,进一步的肯定单层的无法有很好的效果,需要进行堆叠;显然RNN不再只是像CNN那样,前后只是输入输出的联系 直接头尾相连就好,这里需要一个引入一个函数MultiRNNCell来对于RNN进行堆叠,如下:
def get_a_rnncell():
return tf.nn.rnn_cell.BasicLSTMCell(num_units=128)
model=tf.nn.rnn_cell.MultiRNNCell([get_a_rnncell() for _ in range(3)])
>>> model.state_size
(LSTMStateTuple(c=128, h=128), LSTMStateTuple(c=128, h=128), LSTMStateTuple(c=128, h=128))
#包含了三个隐状态情况
>>> h_0=model.zero_state(100,tf.float32)
>>> output,h1=model.call(input_data,h_0)
>>> h1
(LSTMStateTuple(c=<tf.Tensor 'cell_0/cell_0/basic_lstm_cell/add_1:0' shape=(100, 128) dtype=float32>, h=<tf.Tensor 'cell_0/cell_0/basic_lstm_cell/mul_2:0' shape=(100, 128) dtype=float32>), LSTMStateTuple(c=<tf.Tensor 'cell_1/cell_1/basic_lstm_cell/add_1:0' shape=(100, 128) dtype=float32>, h=<tf.Tensor 'cell_1/cell_1/basic_lstm_cell/mul_2:0' shape=(100, 128) dtype=float32>), LSTMStateTuple(c=<tf.Tensor 'cell_2/cell_2/basic_lstm_cell/add_1:0' shape=(100, 128) dtype=float32>, h=<tf.Tensor 'cell_2/cell_2/basic_lstm_cell/mul_2:0' shape=(100, 128) dtype=float32>))
>>> h_0
(LSTMStateTuple(c=<tf.Tensor 'MultiRNNCellZeroState/BasicLSTMCellZeroState/zeros:0' shape=(100, 128) dtype=float32>, h=<tf.Tensor 'MultiRNNCellZeroState/BasicLSTMCellZeroState/zeros_1:0' shape=(100, 128) dtype=float32>), LSTMStateTuple(c=<tf.Tensor 'MultiRNNCellZeroState/BasicLSTMCellZeroState_1/zeros:0' shape=(100, 128) dtype=float32>, h=<tf.Tensor 'MultiRNNCellZeroState/BasicLSTMCellZeroState_1/zeros_1:0' shape=(100, 128) dtype=float32>), LSTMStateTuple(c=<tf.Tensor 'MultiRNNCellZeroState/BasicLSTMCellZeroState_2/zeros:0' shape=(100, 128) dtype=float32>, h=<tf.Tensor 'MultiRNNCellZeroState/BasicLSTMCellZeroState_2/zeros_1:0' shape=(100, 128) dtype=float32>))
顺带说一句 假如我们直接使用之前的 也就是单层的RNN里面的h_0作为初始隐状态信息输入,就会出现TypeError: 'Tensor' object is not iterable.的错误提示,翻看源代码里面的zero_state函数的介绍可以知道,最后实现return _zero_state_tensors(state_size, batch_size, dtype) 是需要调用当前model也就是RNN的隐状态情况的,也就是说初始的h_0其实还是一一对应的,毕竟state_size都是不一样的;
RNN在tf里面的前向
虽然RNN里面有着输出,毕竟神经网络嘛 哪能离得开输出的情况呢。但也能感觉到在RNN里面 其实对于隐状态情况更为关注,翻开BasicRNNCell和BasicLSTMCell的call函数如下,前者参考上面的RNN的结构图来理解,在BasicRNNCell里面其实output和隐状态的值是一样的,不过定义发生了一波转换,才有上图中当前单元的输出y;所以在BasicRNNCell里面state_size和output_size是一样的;
对于后者的BasicLSTMCell来说,依照标准的(output, next_state) = call(input, state)我们可以看到,位于前者的为output,输出的也正是LSTM里面单纯的h,而LSTM输出的隐状态就包含了h和c两部分,可以看到,其实两者的组合得到的结果;
def call(self, inputs, state):
#... 前略
output = self._activation(self._linear([inputs, state]))
return output, output
def call(self, inputs, state):
new_c = (
c * sigmoid(f + self._forget_bias) + sigmoid(i) * self._activation(j))
new_h = self._activation(new_c) * sigmoid(o)
if self._state_is_tuple:
new_state = LSTMStateTuple(new_c, new_h)
else:
new_state = array_ops.concat([new_c, new_h], 1)
return new_h, new_state
综上可以说 其实RNN里面的output_size其实也都是根据state_size来的,同样的,输出的output部分 其实和隐状态是一样的;
顺带多一句嘴的就是 这里合并是使用的tuple(..)的合并;看源代码
dynamic_rnn方法
在上面的介绍 其实已经看到了 单个的RNNCell来说,我们每次调用call函数,来得到对应的output和state信息,在之前的实验中 我们初始化的时候input_data=tf.placeholder(tf.float32,shape=(100,64)),这里单纯的是形如(batch_size,input_size)的格式,这里针对的也还是 如:一个句子里面的一个单词;再具体一点 单层RNNCell针对这样一个句子里面的一个单词 其实就是完成了:对于这个单词 根据h0和x1得到x2和h1;
但 如果我们有着多层的 如上面这个3层的LSTM,针对一个单词 我们就需要调用3次:根据h0和x1得到x2和h1,、根据h1和x2得到x3和h2。。。以此类推;同时 如果不再是一个单词 而是一个句子 比如长度为10 ,那么针对这个长度10的句子,我们又需要调用这个三层LSTM 10次;
这里 可以使用dynamic_rnn直接调用需要次数的call函数;
当然使用起来还是有所不同的,需要对于input进行变形,不同之处就在于这里的输入:
- inputs: If time_major == False (default), this must be a Tensor of shape: [batch_size, max_time, …], or a nested tuple of such elements. If time_major == True, this must be a Tensor of shape:[max_time, batch_size, …], or a nested tuple of such elements. 如果是time_major=True,input的维度是[max_time, batch_size, input_size],反之就是[batch_size, max_time, input_zise];
显然这里的数据我们需要考虑到,序列长度本身的问题,也就是这里输入的形式发生了变化;max_time 其实也就是序列本身的长度,在之前的实验中 我们初始化的时候input_data=tf.placeholder(tf.float32,shape=(100,64)),这里单纯的是形如(batch_size,input_size)的格式,其实更多的也还是针对的是「单词」 这个级别的问题,如果我们考虑序列长度 其实也就变成了到句子级别的问题了;「可以参考这几个网站来理解tf.nn.dynamic_rnn的输出outputs和state含义和tensorflow高阶教程:tf.dynamic_rnn」
经过dynamic_rnn,返回值有两个:output和state,之前也提到过 其输入的input形式相比于单纯的(batch_size,input_size)多了一个max_time的量的考虑,顾名思义 其实也就是对应的句子里面最长句子的单词数目,就像上面所说 其实也是为了效率考虑 从单词变成了句子;
输出的两者:
- outputs. outputs是一个tensor
- 如果time_major==True,outputs形状为 [max_time, batch_size, cell.output_size ](要求rnn输入与rnn输出形状保持一致)
- 如果time_major==False(默认),outputs形状为 [ batch_size, max_time, cell.output_size ]
- state. state是一个tensor。state是最终的状态,也就是序列中最后一个cell输出的状态。一般情况下state的形状为 [batch_size, cell.output_size ],但当输入的cell为BasicLSTMCell时,state的形状为[2,batch_size, cell.output_size ],其中2也对应着LSTM中的cell state和hidden state
可以看到借助于 tf.nn.dynamic_rnn直接输出运行最终的输出还有状态情况,进而也就完成了前向传播过程;
如下一个简单的示范代码 来体现一波其使用:
import tensorflow as tf
import numpy as np
def dynamic_rnn(rnn_type='lstm'):
# 创建输入数据,3代表batch size,6代表输入序列的最大步长(max time),4代表每个序列的维度
X = np.random.randn(3, 6, 4)
# 第二个输入的实际长度为4
X[1, 4:] = 0
#记录三个输入的实际步长
X_lengths = [6, 4, 6]
rnn_hidden_size = 5
if rnn_type == 'lstm':
cell = tf.contrib.rnn.BasicLSTMCell(num_units=rnn_hidden_size, state_is_tuple=True)
else:
cell = tf.contrib.rnn.GRUCell(num_units=rnn_hidden_size)
outputs, last_states = tf.nn.dynamic_rnn(
cell=cell,
dtype=tf.float64,
sequence_length=X_lengths,
inputs=X)
with tf.Session() as session:
session.run(tf.global_variables_initializer())
o1, s1 = session.run([outputs, last_states])
print(np.shape(o1))
print(o1)
print(np.shape(s1))
print(s1)
if __name__ == '__main__':
dynamic_rnn(rnn_type='lstm')
cell类型为LSTM,我们看看输出是什么样子,如下图所示,输入的形状为 [ 3, 6, 4 ],经过tf.nn.dynamic_rnn后outputs的形状为 [ 3, 6, 5 ];「三个数分别代表了batch_size,max_times state_size」state形状为 [ 2, 3, 5 ],包含了两部分 所以第一个数才是2,其中state第一部分为c,代表cell state;第二部分为h,代表hidden state。可以看到hidden state 与 对应的outputs的最后一行是相等的。另外需要注意的是输入一共有三个序列,但第二个序列的长度只有4,可以看到outputs中对应的两行值都为0,所以hidden state对应的是最后一个不为0的部分。tf.nn.dynamic_rnn通过设置sequence_length来实现这一逻辑。
(3, 6, 5)
[[[ 0.0146346 -0.04717453 -0.06930042 -0.06065602 0.02456717]
[-0.05580321 0.08770171 -0.04574306 -0.01652854 -0.04319528]
[ 0.09087799 0.03535907 -0.06974291 -0.03757408 -0.15553619]
[ 0.10003044 0.10654698 0.21004055 0.13792148 -0.05587583]
[ 0.13547596 -0.014292 -0.0211154 -0.10857875 0.04461256]
[ 0.00417564 -0.01985144 0.00050634 -0.13238986 0.14323784]]
[[ 0.04893576 0.14289175 0.17957205 0.09093887 -0.0507192 ]
[ 0.17696126 0.09929577 0.21185635 0.20386451 0.11664373]
[ 0.15658667 0.03952745 -0.03425637 0.00773833 -0.03546742]
[-0.14002582 -0.18578786 -0.08373584 -0.25964601 0.04090167]
[ 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. ]]
[[ 0.18564152 0.01531695 0.13752453 0.17188506 0.19555427]
[ 0.13703949 0.14272294 0.21313036 0.07417354 0.0477547 ]
[ 0.23021792 0.04455495 0.10204565 0.17159792 0.34148467]
[ 0.0386402 0.0387848 0.02134559 0.00110381 0.08414687]
[ 0.01386241 -0.02629686 -0.0733538 -0.03194245 0.13606553]
[ 0.01859433 -0.00585316 -0.04007138 0.03811594 0.21708331]]]
(2, 3, 5)
LSTMStateTuple(c=array([[ 0.00909146, -0.03747076, 0.0008946 , -0.23459786, 0.29565899],
[-0.18409266, -0.30463044, -0.28033809, -0.49032542, 0.12597639],
[ 0.04494702, -0.01359631, -0.06706629, 0.06766361, 0.40794032]]), h=array([[ 0.00417564, -0.01985144, 0.00050634, -0.13238986, 0.14323784],
[-0.14002582, -0.18578786, -0.08373584, -0.25964601, 0.04090167],
[ 0.01859433, -0.00585316, -0.04007138, 0.03811594, 0.21708331]]))
cell类型为GRU,我们看看输出是什么样子,如下图所示,输入的形状为 [ 3, 6, 4 ],经过tf.nn.dynamic_rnn后outputs的形状为 [ 3, 6, 5 ],state形状为 [ 3, 5 ]。可以看到 state 与 对应的outputs的最后一行是相等的。
(3, 6, 5)
[[[-0.05190962 -0.13519617 0.02045928 -0.0821183 0.28337528]
[ 0.0201574 0.03779418 -0.05092804 0.02958051 0.12232347]
[ 0.14884441 -0.26075898 0.1821795 -0.03454954 0.18424161]
[-0.13854156 -0.26565378 0.09567164 -0.03960079 0.14000589]
[-0.2605973 -0.39901657 0.12495693 -0.19295695 0.52423598]
[-0.21596414 -0.63051687 0.20837501 -0.31775378 0.77519457]]
[[-0.1979659 -0.30253523 0.0248779 -0.17981144 0.41815343]
[ 0.34481129 -0.05256187 0.1643036 0.00739746 0.27384158]
[ 0.49703664 0.22241165 0.27344766 0.00093435 0.09854949]
[ 0.23312444 0.156997 0.25482553 0.0138156 -0.02302272]
[ 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. ]]
[[-0.06401732 0.08605342 -0.03936866 -0.02287695 0.16947652]
[-0.1775206 -0.2801672 -0.0387468 -0.20264583 0.58125297]
[ 0.39408762 -0.44066425 0.25826641 -0.18851604 0.36172166]
[ 0.0536013 -0.29902928 0.08891931 -0.03930039 0.0743423 ]
[ 0.02304702 -0.0612499 0.09113458 -0.05169013 0.29876455]
[-0.06711324 0.014125 -0.05856332 -0.05632359 -0.00390189]]]
(3, 5)
[[-0.21596414 -0.63051687 0.20837501 -0.31775378 0.77519457]
[ 0.23312444 0.156997 0.25482553 0.0138156 -0.02302272]
[-0.06711324 0.014125 -0.05856332 -0.05632359 -0.00390189]]
以上代码来自于网络;
CharRNN的实现
这里主要想着实现一个CharRNN,于是这里其实也主要介绍了其中的CharRNN这个类;这里主要说一下其中的相关方法: 可以看到代码中 将:建立输入、建立模型、建立损失函数、建立优化器、训练过程、真是数据的采样、读取模型 这一系列功能都单独成为了一个个函数,进而总体构成了一个CarRNN所需要的相关功能;
emmmm 直接把相关笔记复制过来了 也没太多整理,恩 反正只有自己看(扭头
输入函数的建立
首先是build_inputs()方法,主要用于对于输入数据的建立 可以看到其中完成的工作也就是常见的设置输入数据和target值还有其他相关参数的占位符,恩 顺带放在name_scope里面 这确实是个好习惯 也更加明显和醒目「改写成tensorboard的形式也方便」
于是第一个函数build_inputs()如下:
def build_inputs(self):
with tf.name_scope('inputs'):
self.inputs = tf.placeholder(tf.int32, shape=(
self.num_seqs, self.num_steps), name='inputs')
#self.num_seqs表示序列的多少 也就是一个batch内有多少序列「多少句子」
#self.num_steps就是一个句子的长度了
self.targets = tf.placeholder(tf.int32, shape=(
self.num_seqs, self.num_steps), name='targets')
self.keep_prob = tf.placeholder(tf.float32, name='keep_prob')
# 对于中文,需要使用embedding层
# 英文字母没有必要用embedding层
if self.use_embedding is False:
self.lstm_inputs = tf.one_hot(self.inputs, self.num_classes)
#经过one-hot形式的变形 因而也就变形为
#[self.num_seqs, self.num_steps,self.num_classes]的形式
else:
with tf.device("/cpu:0"):
embedding = tf.get_variable('embedding', [self.num_classes, self.embedding_size])
self.lstm_inputs = tf.nn.embedding_lookup(embedding, self.inputs)
可以看到 一开始的时候 我们将input和target设置成为相同shape的形式,当然后面在build_loss(self)里面target也会进行一样的变形;可以看到变形的操作都是类似的要么是tf.one_hot要么加入了个embedding层,使用了tf.nn.embedding_lookup,但目的都是一样的:
首先来看tf.one_hot
>>> a=tf.constant([[1,2],[2,3]])
>>> num_classes=10
>>> b=tf.one_hot(a,num_classes)
>>> a
<tf.Tensor 'Const:0' shape=(2, 2) dtype=int32>
>>> b
<tf.Tensor 'one_hot:0' shape=(2, 2, 10) dtype=float32>
然后是tf.nn.embedding_lookup,用法的话类似下面,这个函数其实是个很有趣的函数,就意义而言是从c里面按照a的要求进行抽取参数,这里就不展开来说了,只是可能会发现这里如果按照上面的写法 那么self.use_embedding is False或者为True输出的self.lstm_inputs就是不同的shape了「可能是因为针对的问题不同?所以不同的输入类型?」
- 为
False的时候 输出的为[self.num_seqs, self.num_steps,self.num_classes]的形式 - 为
True的时候,输出为[self.num_seqs, self.num_steps,self.embedding_size]的形式
>>> c=tf.get_variable(name="c",shape=[10,128])
>>> d=tf.nn.embedding_lookup(c,a)
>>> d
<tf.Tensor 'embedding_lookup:0' shape=(2, 2, 128) dtype=float32>
回头看吧,虽然不同的输入 看样子不会影响最后的输出,毕竟是使用和没使用了embedding层 输入肯定会有这区别,毕竟相当于针对了不同的问题 多加了一个曾 但emmm 还是不太了解啊,看完对于中文的word2vec后 再来拆开来对比再说吧;
完成了对于输入的相关设置后 我们就需要建立起来模型来处理我们的输入了;
模型函数的建立
函数的话 前面说了很多,包含RNN里面多层应该怎么构建、怎么不多次调用call就完成了RNND前向传播等,但还是有所不同的 首先在网络层上的一个改变就是在每个LSTM之后加上了一个tf.nn.rnn_cell.DropoutWrapper 也就是dropout操作;
在完成对于RNN的构造之后,经过RNN的前向传播后,我们得到关于RNN的输出,在之前的介绍中我们知道关于LSTM的输出如下图:
根据RNN的前向传播的公式也可以知道,为了得到具体的输出概率还是需要对于隐状态参数进行加权操作如下:$y_t=softmax(Vh_t+c)$
进一步的 经过了tf.nn.dynamic_rnn后的输出,为[batch_size,max_times state_size],axis=1的位置上 其实表示了一个句子中多个单词,那么我们先使用
同样的还需要对于输出进行变形方便后面进行构建损失函数;
根据之前的介绍,可以知道经过了tf.nn.dynamic_rnn后的输出,为[batch_size,max_times state_size],然后进行依照axis=1进行合并 然后reshape后 构建一个单层网络用于输出概率;
这里使用
tf.concat其实我没太看懂,毕竟理论上输出就是[batch_size,max_times state_size]再使用也是没什么意义的,只要直接reshape把前面两个axis的合并就好了; 但转念一想 是否是因为尽管是一个batch 但每次还是输入一个句子这样的操作,因而最后输出的一系列的[max_times state_size]的tensor 也就是形如[tenor_1,tensor_2…]这样的合并 因而需要合并,但这样想的话 不是应该在[max_times state_size]里面的axis=0的位置进行合并吗? emmm 不是很懂; 好吧 虽然又把tf.nn.dynamic_rnn和tf.nn.rnn_cell.BasicLSTMCell源代码翻出来看了一波,想了想可能是因为输出使用的tuple的原因,但reshape照样直接就能用的啊; 顺带说一句假如真的是这样操作:>> c=tf.concat([a,b],1) >> c <tf.Tensor 'concat_2:0' shape=(2, 4) dtype=int32>反倒是会有这样的结果; 直接针对后面的state_size来进行合并了; 翻看了一波其他的实现 其实就和我之前想的差不多:毕竟本质上也只为了将
[batch_size,max_times state_size]的隐状态输出变为[batch_size*max_times state_size]的形式 参考下面代码知道 所要做的目的也都是一样的:>> a=tf.constant([[1,2],[2,3]]) >> a=tf.constant([[6,5],[3,4]]) >> b=tf.constant([[1,2],[2,3]]) >> a <tf.Tensor 'Const_1:0' shape=(2, 2) dtype=int32> >> b <tf.Tensor 'Const_2:0' shape=(2, 2) dtype=int32> >> c=tf.concat([a,b],0) >> c <tf.Tensor 'concat:0' shape=(4, 2) dtype=int32> >> d=tf.reshape(tf.concat([a,b],1),[-1,2]) >> d <tf.Tensor 'Reshape:0' shape=(4, 2) dtype=int32> >> with tf.Session() as sess: ... print(sess.run(c)) [[6 5] [3 4] [1 2] [2 3]] >> with tf.Session() as sess: ... print(sess.run(d)) [[6 5] [1 2] [3 4] [2 3]]emmm 这么看其实都是一样的操作,不知道源代码里面的是否有区别 之后还是最好再需要单独的修改来对比试验一波;
tf.concat(self.lstm_outputs, 0)和tf.concat(self.lstm_outputs, 1)加上tf.reshape(seq_output, [-1, self.lstm_size])
以下为全部代码;
def build_lstm(self):
# 创建单个cell并堆叠多层
def get_a_cell(lstm_size, keep_prob):
lstm = tf.nn.rnn_cell.BasicLSTMCell(lstm_size)
drop = tf.nn.rnn_cell.DropoutWrapper(lstm, output_keep_prob=keep_prob)
return drop
with tf.name_scope('lstm'):
cell = tf.nn.rnn_cell.MultiRNNCell(
[get_a_cell(self.lstm_size, self.keep_prob) for _ in range(self.num_layers)]
)
self.initial_state = cell.zero_state(self.num_seqs, tf.float32)
# 通过dynamic_rnn对cell展开时间维度
self.lstm_outputs, self.final_state = tf.nn.dynamic_rnn(cell, self.lstm_inputs, initial_state=self.initial_state)
# 通过lstm_outputs得到概率
seq_output = tf.concat(self.lstm_outputs, 1)
x = tf.reshape(seq_output, [-1, self.lstm_size])
with tf.variable_scope('softmax'):
softmax_w = tf.Variable(tf.truncated_normal([self.lstm_size, self.num_classes], stddev=0.1))
softmax_b = tf.Variable(tf.zeros(self.num_classes))
self.logits = tf.matmul(x, softmax_w) + softmax_b
self.proba_prediction = tf.nn.softmax(self.logits, name='predictions')
定义损失函数
可以看到再上一步完成对于输出的状态值增加了一个softmax层,进而输出相关的预测结果,但内部的shape变化 其实还是:从状态输入的[batch_size*max_times ,state_size] 经过单层变为[batch_size*max_times,num_classes] 在经过softmax,预测计算对应位置的softmax值,还是[batch_size*max_times,num_classes] ,当然 在建立loss的时候,tensorflow里面交叉熵函数也就有着softmax的操作了,这里的softmax的操作 更多的还是用于predict;
于是在损失的函数build_loss(self)里面 更多的也只是两个变形,将target首先就像之前input一样进行one_hot变形,然后再reshape成为和预测值一样的shape,最后 直接使用交叉熵计算损失函数;
def build_loss(self):
with tf.name_scope('loss'):
y_one_hot = tf.one_hot(self.targets, self.num_classes)
y_reshaped = tf.reshape(y_one_hot, self.logits.get_shape())
loss = tf.nn.softmax_cross_entropy_with_logits(logits=self.logits, labels=y_reshaped)
self.loss = tf.reduce_mean(loss)
优化器
定义完损失函数后,再就是优化器了,其实拆成两个函数 emmm 虽然很明显和很好理解,但也不是那么流畅了倒是;优化器里面 使用clipping gradients来防止梯度爆炸的问题 具体如下:
def build_optimizer(self):
# 使用clipping gradients
tvars = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(self.loss, tvars), self.grad_clip)
train_op = tf.train.AdamOptimizer(self.learning_rate)
self.optimizer = train_op.apply_gradients(zip(grads, tvars))
train和predict以及load函数
之后的就是一个train函数和一个predict函数了,还有就是读取模型的函数:
def train(self, batch_generator, max_steps, save_path, save_every_n, log_every_n):
self.session = tf.Session()
with self.session as sess:
sess.run(tf.global_variables_initializer())
# Train network
step = 0
new_state = sess.run(self.initial_state)
for x, y in batch_generator:
step += 1
start = time.time()
feed = {self.inputs: x,
self.targets: y,
self.keep_prob: self.train_keep_prob,
self.initial_state: new_state}
batch_loss, new_state, _ = sess.run([self.loss,
self.final_state,
self.optimizer],
feed_dict=feed)
end = time.time()
# control the print lines
if step % log_every_n == 0:
print('step: {}/{}... '.format(step, max_steps),
'loss: {:.4f}... '.format(batch_loss),
'{:.4f} sec/batch'.format((end - start)))
if (step % save_every_n == 0):
self.saver.save(sess, os.path.join(save_path, 'model'), global_step=step)
if step >= max_steps:
break
self.saver.save(sess, os.path.join(save_path, 'model'), global_step=step)
def sample(self, n_samples, prime, vocab_size):
samples = [c for c in prime]
sess = self.session
new_state = sess.run(self.initial_state)
preds = np.ones((vocab_size, )) # for prime=[]
for c in prime:
x = np.zeros((1, 1))
# 输入单个字符
x[0, 0] = c
feed = {self.inputs: x,
self.keep_prob: 1.,
self.initial_state: new_state}
preds, new_state = sess.run([self.proba_prediction, self.final_state],
feed_dict=feed)
c = pick_top_n(preds, vocab_size)
# 添加字符到samples中
samples.append(c)
# 不断生成字符,直到达到指定数目
for i in range(n_samples):
x = np.zeros((1, 1))
x[0, 0] = c
feed = {self.inputs: x,
self.keep_prob: 1.,
self.initial_state: new_state}
preds, new_state = sess.run([self.proba_prediction, self.final_state],
feed_dict=feed)
c = pick_top_n(preds, vocab_size)
samples.append(c)
return np.array(samples)
def load(self, checkpoint):
self.session = tf.Session()
self.saver.restore(self.session, checkpoint)
print('Restored from: {}'.format(checkpoint))